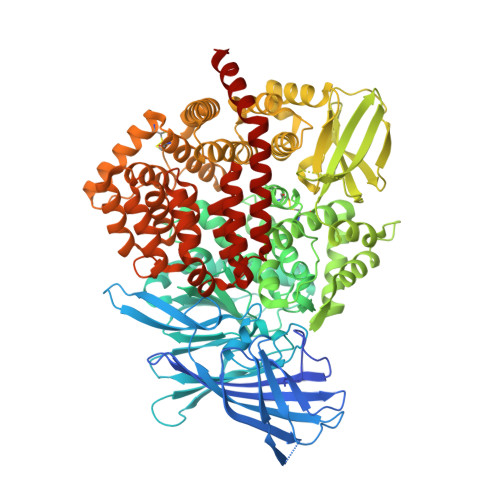
The endoplasmic-reticulum aminopeptidase ERAP1 processes antigenic peptides for loading on MHC-I proteins and recognition by CD8 T cells as they survey the body for infection and malignancy. Crystal structures have revealed ERAP1 in either open or closed conformations, but whether these occur in solution and are involved in catalysis is not clear. Here, we assess ERAP1 conformational states in solution in the presence of substrates, allosteric activators, and inhibitors by small-angle X-ray scattering. We also characterize changes in protein conformation by X-ray crystallography, and we localize alternate C-terminal binding sites by chemical crosslinking. Structural and enzymatic data suggest that the structural reconfigurations of ERAP1 active site are physically linked to domain closure and are promoted by binding of long peptide substrates. These results clarify steps required for ERAP1 catalysis, demonstrate the importance of conformational dynamics within the catalytic cycle, and provide a mechanism for the observed allosteric regulation and Lys/Arg528 polymorphism disease association.
Organizational Affiliation:
Department of Pathology, University of Massachusetts Medical School, Worcester, MA, USA.
Department of Chemistry, National and Kapodistrian University of Athens, Athens, Greece.
Department of Pathology, University of Massachusetts Medical School, Worcester, MA, USA. Lawrence.Stern@umassmed.edu.
AA [auth a], AB [auth 0], BA [auth b], BB [auth 1], CA [auth c],
AA [auth a], AB [auth 0], BA [auth b], BB [auth 1], CA [auth c], CB [auth 2], DA [auth d], DB [auth 3], EA [auth e], EB [auth 4], FA [auth f], FB [auth 5], GA [auth g], GB [auth 6], HA [auth h], HB [auth 7], IA [auth i], IB [auth 8], JA [auth j], JB [auth 9], KA [auth k], KB [auth AA], LA [auth l], LB [auth BA], MA [auth m], MB [auth CA], NA [auth n], NB [auth DA], OA [auth o], PA [auth p], QA [auth q], RA [auth r], SA [auth s], TA [auth t], UA [auth u], VA [auth v], W, WA [auth w], X, XA [auth x], Y, YA [auth y], Z, ZA [auth z]