Crystal Structure of Proteus vulgaris Chondroitin Sulfate ABC Lyase I at 1.9 Angstroms Resolution
Huang, W., Lunin, V.V., Li, Y., Suzuki, S., Sugiura, N., Miyazono, H., Cygler, M.(2003) J Mol Biology 328: 623-634
- PubMed: 12706721 Search on PubMed
- DOI: https://doi.org/10.1016/s0022-2836(03)00345-0
- Primary Citation Related Structures:
1HN0 - PubMed Abstract:
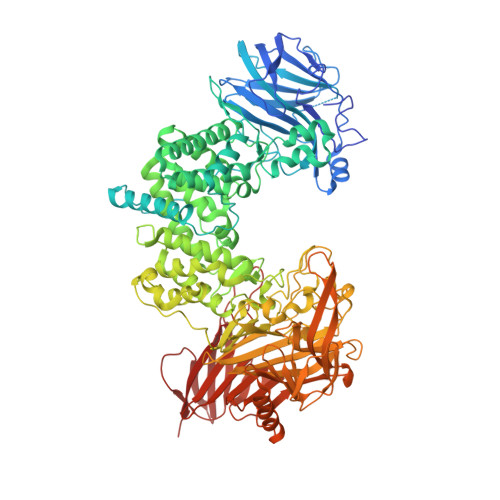
Chondroitin Sulfate ABC lyase I from Proteus vulgaris is an endolytic, broad-specificity glycosaminoglycan lyase, which degrades chondroitin, chondroitin-4-sulfate, dermatan sulfate, chondroitin-6-sulfate, and hyaluronan by beta-elimination of 1,4-hexosaminidic bond to unsaturated disaccharides and tetrasaccharides. Its structure revealed three domains. The N-terminal domain has a fold similar to that of carbohydrate-binding domains of xylanases and some lectins, the middle and C-terminal domains are similar to the structures of the two-domain chondroitin lyase AC and bacterial hyaluronidases. Although the middle domain shows a very low level of sequence identity with the catalytic domains of chondroitinase AC and hyaluronidase, the residues implicated in catalysis of the latter enzymes are present in chondroitinase ABC I. The substrate-binding site in chondroitinase ABC I is in a wide-open cleft, consistent with the endolytic action pattern of this enzyme. The tryptophan residues crucial for substrate binding in chondroitinase AC and hyaluronidases are lacking in chondroitinase ABC I. The structure of chondroitinase ABC I provides a framework for probing specific functions of active-site residues for understanding the remarkably broad specificity of this enzyme and perhaps engineering a desired specificity. The electron density map showed clearly that the deposited DNA sequence for residues 495-530 of chondroitin ABC lyase I, the segment containing two putative active-site residues, contains a frame-shift error resulting in an incorrectly translated amino acid sequence.
- Biotechnology Research Institute, National Research Council of Canada, 6100 Royalmount Avenue, Montréal, Québec, Canada H4P 2R2.
Organizational Affiliation: